Edge AI for Threat Detection: Privacy-Preserving On-Device Anomaly Detection Accelerates Zero-Trust Security in IoT
Practical guide to building privacy-preserving on-device anomaly detection for IoT — accelerating zero-trust with Edge AI, TinyML, and lightweight models.
Edge AI for Threat Detection: Privacy-Preserving On-Device Anomaly Detection Accelerates Zero-Trust Security in IoT
Introduction
IoT fleets are multiplying. So are the threat vectors. Centralized analytics and cloud pipelines struggle with bandwidth, latency, and — increasingly — privacy constraints. On-device anomaly detection using Edge AI directly addresses these problems: it detects suspicious behavior at the source, preserves privacy by keeping raw telemetry local, and enforces zero-trust principles with fast, deterministic responses.
This post is a developer-focused, practical guide to designing and deploying privacy-preserving on-device anomaly detection for IoT. You’ll get architecture patterns, model choices, runtime optimization tips, and a compact code example you can adapt for constrained devices.
Why on-device anomaly detection matters
- Latency: Some attacks need sub-second mitigation. Local inference delivers immediate detection and response without cloud round-trips.
- Privacy: Sensitive telemetry (audio, video, health data) never leaves the device. That reduces compliance overhead and attack surface.
- Resilience: Devices keep protecting themselves during network loss or when connectivity is intermittent.
- Scalability: Offloading inference reduces cloud costs and central processing bottlenecks.
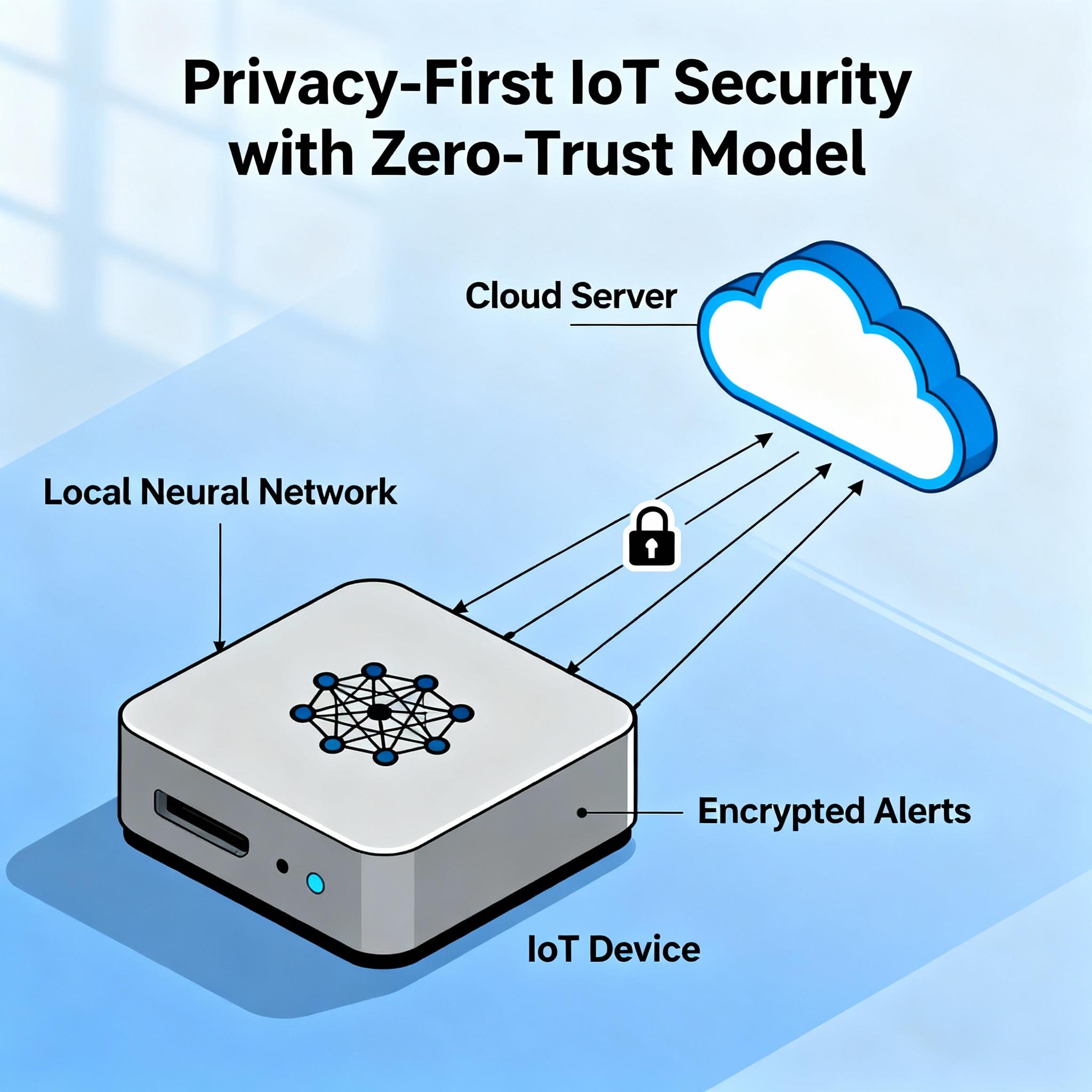
From a security standpoint, on-device anomaly detectors act as the first line of defense in a zero-trust architecture: every device continuously verifies behavior, issues alerts, or quarantines itself when anomalies are detected.
High-level architecture patterns
Pattern 1 — Local detection, central orchestration
Devices run lightweight anomaly detectors that emit compact alerts (scores, feature hashes, metadata) to a central system. The cloud aggregates alerts for correlation, threat intelligence, and model updates. This pattern preserves privacy because raw data stays local.
Pattern 2 — Local enforcement with federated learning
Devices perform detection and also participate in federated learning to improve models without sharing raw data. Only model updates or gradients are exchanged — often aggregated and differential-private — to protect data privacy.
Pattern 3 — Hybrid streaming with on-device preprocessing
Devices preprocess and compress telemetry into features locally and stream features to the cloud for heavier processing when needed. Use this when you need rich analytics but still want to reduce raw-data exposure.
Model choices and trade-offs
Pick the simplest model that reliably separates normal from anomalous behavior. Simpler models mean smaller memory footprint, faster inference, and easier explainability.
- Statistical baselines: rolling averages and simple thresholding. Extremely cheap and interpretable but brittle to concept drift.
- One-class models: One-Class SVM, Isolation Forest. Moderate compute, reasonable for tabular telemetry.
- Autoencoders: Lightweight neural autoencoders reconstruct inputs; large reconstruction error signals anomalies. Good for multivariate time-series.
- Deep SVDD / single-class networks: More complex but performant when you have abundant normal-only data.
When privacy is the priority, choose models that produce compact, non-invertible outputs. Avoid architectures that could be reversed to reconstruct raw inputs.
Practical constraints: what to optimize for
- Memory: Keep model size within the device RAM and flash budgets (for microcontrollers, target 512KB RAM ranges or smaller).
- Compute and energy: Favor integer quantization, pruning, and batch size 1 inference.
- Latency: Ensure inference time meets detection SLA (for many OT use-cases this is tens to hundreds of milliseconds).
- Explainability: For security teams, prefer models that provide interpretable scores and simple debug signals.
Tooling: TensorFlow Lite Micro, ONNX Runtime for mobile, ARM CMSIS-NN, and vendor SDKs (EdgeTPU, NPU) are your go-to options.
Privacy-preserving techniques
- Local-only data retention: store raw telemetry for a minimal window and purge automatically.
- Share only alerts: send
device_id,timestamp,anomaly_score, and short context vectors — not raw payloads. - Differential privacy & secure aggregation: if you must collect updates, apply noise and aggregate across devices so individual data is indistinguishable.
- Model update policy: sign and authenticate models; use secure boot and attestation to avoid model hijacking.
When publishing a config or observable, wrap sensitive configuration in compact JSON-like objects. For example: { "model": "autoencoder", "threshold": 0.05 }.
Example: lightweight autoencoder for streaming telemetry
Below is a compact Python-like example that demonstrates the on-device pipeline for streaming telemetry (sensor vectors) with a small autoencoder. The example focuses on simplicity and clarity: feature normalization, reconstruction error, threshold, and local alert emission.
# Pseudocode — streaming anomaly detector (autoencoder)
class StreamingAutoencoder:
def __init__(self, model, mean, scale, threshold):
self.model = model # tiny neural net optimized for edge
self.mean = mean # per-feature mean
self.scale = scale # per-feature std or scale
self.threshold = threshold # empirically chosen
def preprocess(self, x):
# normalize features
return [(xi - m) / s if s != 0 else 0.0 for xi, m, s in zip(x, self.mean, self.scale)]
def infer(self, x):
# run optimized inference path (quantized model)
return self.model.forward(x)
def reconstruct_error(self, x, xr):
# mean squared error per sample
return sum((a - b) ** 2 for a, b in zip(x, xr)) / len(x)
def process_sample(self, raw_x):
x = self.preprocess(raw_x)
xr = self.infer(x)
err = self.reconstruct_error(x, xr)
if err > self.threshold:
self.emit_alert(err, raw_x)
def emit_alert(self, score, context):
# only send compact alert data; do NOT send raw_x
alert = {
"score": score,
"time": int(time.time()),
"features_hash": hash(tuple(context)) & 0xFFFFFFFF
}
telemetry_queue.push(alert)
This skeleton should be adapted to run with a TinyML runtime and compiled for your target. Replace floating-point ops with quantized integer math for microcontrollers, and use hardware-accelerated kernels where available.
Deployment and lifecycle
- Model training and validation: train on representative normal behavior. Validate with synthetic and real anomalies if available.
- Threshold selection: calibrate using validation data and set conservative thresholds to reduce false positives.
- Model packaging: quantize, prune, and convert to target runtime. Include a lightweight metadata blob with version and checksum.
- Secure delivery: sign models and distribute via OTA updates. Use device attestation to verify authenticity before activation.
- Telemetry policy: only export minimal alert data. Maintain local logs for a bounded retention period for debugging under secure access.
- Monitoring and retraining: monitor alert rates and drift; schedule periodic retraining using federated updates or aggregated anonymized statistics.
Edge cases and gotchas
- Concept drift: normal behavior evolves. Implement automatic threshold refresh, periodic retraining, or a supervised feedback loop from analysts.
- Adversarial inputs: attackers know you run a detector. Use ensemble methods and randomized thresholds to increase robustness.
- Resource starvation: fallback to simple statistical checks if the model cannot run due to CPU or memory contention.
Summary — Checklist for building privacy-preserving on-device anomaly detection
- Architecture
- Run detection locally; export only compact alerts.
- Choose hybrid pattern if central analytics are required.
- Models
- Start with simple models; use autoencoders or one-class models for multivariate signals.
- Prefer models that are hard to invert to protect raw data.
- Optimization
- Quantize and prune. Use vendor NN accelerators where available.
- Measure latency, memory, and energy on actual hardware.
- Security & privacy
- Sign and attest model updates.
- Retain raw data locally for minimal time; export only alerts and non-reconstructible context.
- Operations
- Monitor alert rates and drift.
- Use federated or aggregated updates to improve models without leaking raw data.
On-device anomaly detection is not a full replacement for cloud analytics, but it is an essential component of a modern zero-trust IoT strategy. When designed correctly, Edge AI gives you low-latency defenses, privacy guarantees, and operational resilience — all at the device level.
Quick checklist (copy-paste)
- Validate normal-only training data.
- Choose an interpretable, compact model.
- Quantize to int8 and test on device.
- Implement thresholding and local alerting.
- Sign models and enable attestation.
- Monitor drift and schedule retraining.
Implementing privacy-preserving on-device anomaly detection tightens your zero-trust posture and scales your security gracefully. Start with a tiny model, measure on real hardware, and iterate from there.