Federated Learning at the Edge: A practical blueprint for privacy-preserving on-device AI across IoT and mobile devices
A practical, engineer-focused blueprint for deploying federated learning on IoT and mobile devices, covering architecture, secure aggregation, compression, and deployment.
Federated Learning at the Edge: A practical blueprint for privacy-preserving on-device AI across IoT and mobile devices
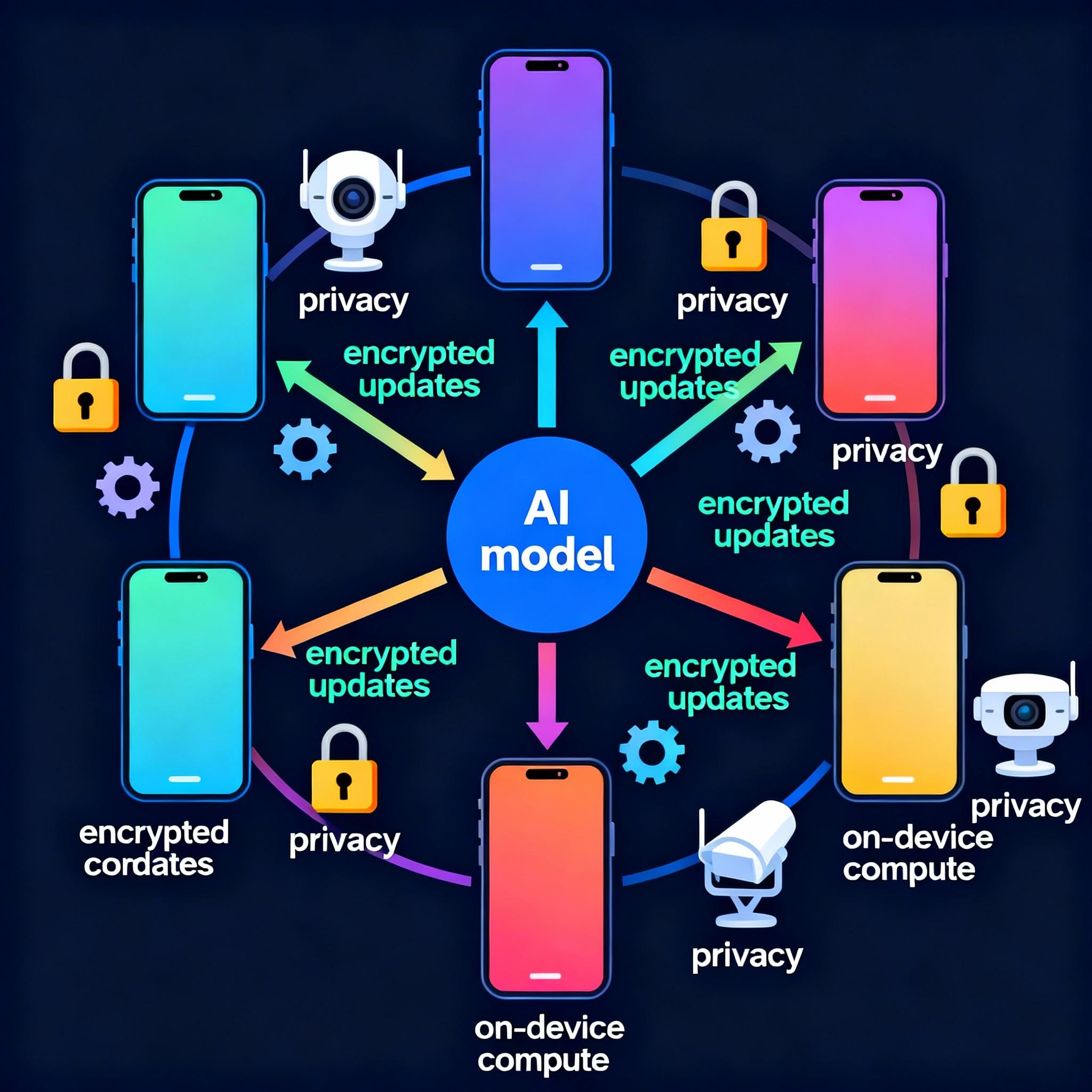
Deploying machine learning to the edge means dealing with constrained compute, intermittent connectivity, and — increasingly — strict privacy expectations. Federated Learning (FL) offers a different tradeoff: move model training to devices, not data. This post gives a practical, engineer-focused blueprint for building privacy-preserving FL systems across mobile and IoT fleets.
We cover architecture, client and server responsibilities, communication patterns, privacy primitives (secure aggregation and differential privacy), and engineering considerations: compression, fault tolerance, incentives, and monitoring. Expect concrete patterns and a runnable conceptual example you can adapt.
Why federated learning at the edge
- Privacy: raw data never leaves the device. Only model updates go to the server.
- Bandwidth efficiency: aggregate smaller updates rather than centralizing full datasets.
- Personalization: on-device fine-tuning lets models adapt to local behavior.
Tradeoffs: training heterogeneity (non-IID data), variable compute, and complex orchestration. The blueprint below addresses these.
High-level architecture
- Orchestration server (Coordinator): schedules rounds, tracks client states, verifies updates, and performs secure aggregation and model update.
- Device clients: perform local training on-device, compute an update (weight delta or gradient), apply compression and privacy transforms, then send the update.
- Aggregation module: collects encrypted/obfuscated updates and computes the global model update.
- Monitoring and analytics: tracks performance metrics without collecting raw user data.
Diagram (concept):
- Coordinator → selects clients → sends global model
- Clients → local training → send encrypted updates
- Aggregator → aggregates → updates global model → publishes new model
Client lifecycle and responsibilities
Clients run a lightweight FL client that performs these steps:
- Receive model snapshot and config (learning rate,
local_epochs, compression config). - Validate model fingerprint to avoid stale updates.
- Train locally on private dataset for
local_epochswith minibatches. - Compute update: weight delta or averaged gradient.
- Apply privacy mechanisms: clipping, noise (for DP), and secure aggregation pre-processing.
- Compress (quantize/sparsify) and upload.
- Await acknowledgement; retry if needed.
Important client-side constraints:
- Allow training only on charger / Wi-Fi / low CPU load for battery-sensitive devices.
- Limit memory footprint and use streaming minibatches if dataset is large.
- Use deterministic checkpoints to resume interrupted training.
Client pseudo-workflow
- Validate
round_idandmodel_version. - If eligible, load
global_modelandtraining_config. - For
local_epochsepochs: iterate minibatches, update model. - Compute
delta = local_model - global_model. - Clip
deltaby global normCand add noise for DP (if enabled). - Send compressed
deltato server via secure channel.
Server orchestration and aggregation
Coordinator responsibilities:
- Client selection: random sampling, stratified sampling, or incentive-based selection.
- Round management: track expected clients and time windows.
- Secure aggregation: ensure the server sees only the aggregate.
- Model update: weighted averaging (FedAvg) or more advanced optimizers.
Aggregation pattern (FedAvg): weighted average of client updates by local dataset size. If using secure aggregation, clients mask their updates so server can only unmask the sum.
Robust aggregation options
- FedAvg (weighted mean) — baseline.
- Trimmed mean or median-based aggregation — robust to Byzantine clients.
- Adaptive optimizers (server-side): apply momentum or Adam-like updates on aggregated gradients.
Secure aggregation and differential privacy
Privacy stack commonly combines secure aggregation with differential privacy (DP):
- Secure aggregation: prevents server from seeing individual updates. Implementations use pairwise masks or threshold cryptography so only the sum is revealed.
- Differential privacy: add calibrated noise to the aggregated result (central DP) or to each client update (local DP) to bound information leakage.
Choose the order carefully: secure aggregation without DP protects individual updates from the server, but if the server is compromised or insiders collude, DP on the aggregate provides a provable leakage bound.
> Tip: In practice, combine secure aggregation for confidentiality in transit and DP on the aggregator output to provide end-to-end guarantees.
Communication efficiency: compression and sparsification
Network is often the bottleneck. Two common patterns:
- Quantization: reduce precision (8-bit, 4-bit, or custom float formats). Use stochastic quantization to preserve unbiasedness.
- Sparsification: send only top-k updates or random sketching (count sketch). Use error-feedback on client to accumulate dropped updates.
Example: top-k with error compensation
- On client: compute
delta, select top-k largest absolute entries, send indices+values, store residual =delta - sentfor next round. - On server: apply sparse update to model. This reduces payload dramatically for large models.
A concise code example (client-side training loop)
Below is a compact Python-flavored pseudo-implementation of the client training and upload flow. This is conceptual and omits networking primitives.
def client_round(global_model, local_dataset, config):
local_model = copy_model(global_model)
opt = SGD(local_model.parameters(), lr=config['lr'])
for epoch in range(config['local_epochs']):
for x, y in local_dataset:
loss = loss_fn(local_model(x), y)
loss.backward()
opt.step()
opt.zero_grad()
# compute delta
delta = model_weights(local_model) - model_weights(global_model)
# clip by L2 norm
norm = l2_norm(delta)
if norm > config['clip_norm']:
delta = delta * (config['clip_norm'] / norm)
# optionally add DP noise
if config.get('dp_noise_scale'):
delta += gaussian_noise(scale=config['dp_noise_scale'])
# compress (top-k example)
indices, values, residual = top_k_compress(delta, k=config['top_k'], residual_buffer=config['residual'])
# send indices+values to server (over secure channel / with masking for secure aggregation)
send_update(indices, values, metadata={'n': len(local_dataset)})
This example uses top_k_compress with an error-feedback residual_buffer stored on device to keep accuracy.
Handling heterogeneity, stragglers, and failures
- Deadlines: set a round timeout. Proceed without late clients and use robust aggregators to avoid bias.
- Participant churn: maintain client state server-side; use opportunistic sampling to keep rounds moving.
- Model versioning: embed model fingerprints to avoid mixing rounds.
Monitoring and validation without raw data
- Evaluate on holdout public datasets if available.
- Use privacy-preserving metrics: clients can compute local evaluation metrics and send aggregated counts/averages via secure aggregation.
- Track model drift, per-cohort performance, and fairness metrics using aggregated signals.
Security considerations
- Authenticate clients with device certificates to prevent Sybil attacks.
- Use attestation (TEE) where available to ensure client code integrity.
- Rate-limit and profile updates to detect anomalous behavior (e.g., poisoning attempts).
Deployment checklist and engineering tips
- Start small: prototype with a small fleet and public datasets.
- Baseline: implement FedAvg first, add secure aggregation and DP after you validate training dynamics.
- Measure cost: track CPU, battery, and bandwidth on representative devices.
- Use modular design: separate orchestrator, aggregation, and transport layers.
- Implement client-side resumption and deterministic seeding for reproducibility.
Summary checklist
- Architecture
- Orchestrator for rounds and selection
- Secure aggregator for confidentiality
- Lightweight client for local training
- Privacy
- Combine secure aggregation with DP on the aggregate
- Implement clipping and noise calibration
- Efficiency
- Apply quantization and sparsification with error feedback
- Schedule training on Wi-Fi/charger and limit resource use
- Robustness
- Use timeouts, robust aggregation, and client authentication
- Monitor aggregated metrics and model health
Final notes
Federated learning at the edge is an engineering problem as much as a research one. Start with a minimal working pipeline: reliable client updates, round orchestration, and clear monitoring. Layer on privacy primitives and compression once you have stable training dynamics. Prioritize reproducibility, security, and a path to incremental deployment.
If you want a hands-on follow-up, I can provide a reference implementation using TensorFlow Federated or a sketch of a secure-aggregation protocol with pairwise masks tuned for mobile devices.