On-device Federated Learning for Privacy-Preserving AI on Edge IoT Devices: A Practical Blueprint for 2025
A practical 2025 blueprint for on-device federated learning on edge IoT: architecture, privacy, communication, model optimization, and deployment steps.
On-device Federated Learning for Privacy-Preserving AI on Edge IoT Devices: A Practical Blueprint for 2025
Introduction
By 2025, the number of intelligent edge IoT devices will be massive and the tolerance for sending raw user data to centralized clouds will be lower than ever. Federated learning (FL) lets you train models across many devices while keeping raw data local. This post gives a practical blueprint for implementing on-device FL on constrained IoT hardware, focusing on privacy, communication efficiency, model optimization, and production deployment.
This is not a conceptual primer. It’s a hands-on guide for engineers designing production FL pipelines for real-world edge fleets. Expect architecture diagrams in prose, engineering trade-offs, a runnable client pseudocode example, and a checklist you can take into design reviews.
Why on-device FL on IoT matters in 2025
- Privacy compliance and user trust: minimizing raw data movement reduces regulatory risk and increases user acceptance.
- Latency and offline operation: local training enables personalization when cloud connectivity is intermittent.
- Bandwidth and cost: sending model updates is far cheaper than streaming raw sensor data.
But on-device FL introduces tough constraints:
- Devices are CPU/RAM-limited and energy-constrained.
- Connectivity is intermittent and asymmetric.
- Heterogeneous hardware and non-iid data across clients.
You need a strategy that treats these constraints as first-class design points.
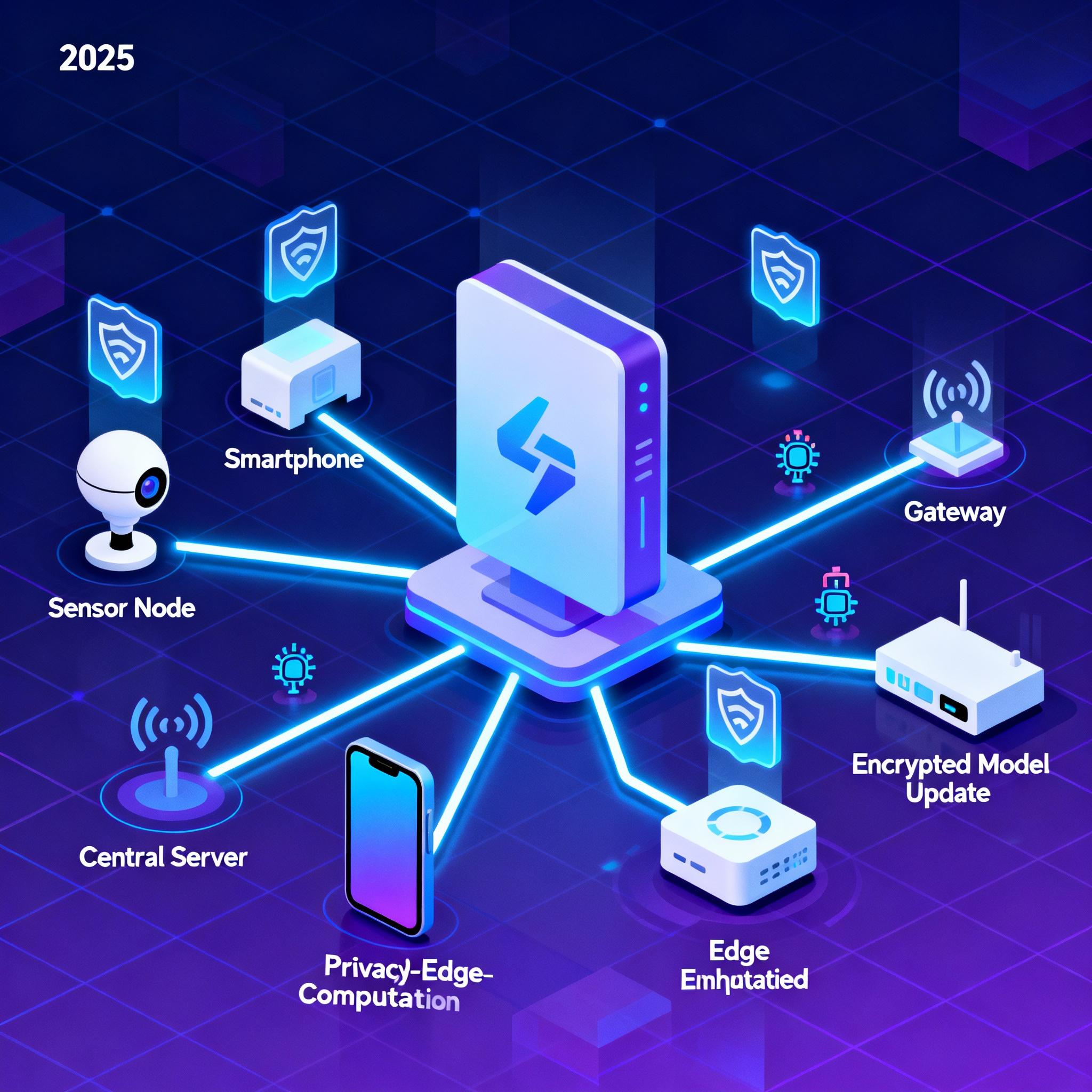
High-level architecture
The architecture has three main layers:
- Device clients: each device runs a lightweight training loop on local data and reports secure updates.
- Aggregation server: orchestrates rounds, aggregates updates securely, and updates the global model.
- Monitoring and deployment: tracks model health, drift, and pushes updates to the device fleet.
Key components and responsibilities:
- Client runtime: lightweight training runtime with model loader, optimizer, and upload agent.
- Secure channel: transport-level encryption and authentication for uploads.
- Secure aggregation and differential privacy: prevent sensitive recovery of client data from updates.
- Compression/quantization: reduce upload size.
- Orchestration: schedule client participation to balance battery and network cost.
Privacy: secure aggregation and differential privacy
Privacy is central but often misunderstood. Two building blocks are mandatory in production:
- Secure aggregation: cryptographic protocols to allow the server to see only the aggregate of client updates, not individual contributions.
- Differential privacy (DP): add calibrated noise to aggregated updates so that the presence of any single client’s data is bounded.
Secure aggregation reduces risk from server compromise. DP protects against inference from aggregate outputs. Use both for high-threat environments.
Practical notes:
- Use threshold-based secure aggregation that tolerates a fraction of dropouts. Dropout rates are higher on IoT fleets, so the protocol must handle missing clients.
- Implement DP at the aggregator to avoid degrading local utility excessively. Calibrate noise using realistic client participation counts.
Communication strategies for constrained networks
Minimize bytes.
- Sparse updates: send only meaningful parameter deltas or just layers that change.
- Quantization: use 8-bit or fewer for gradients and model parameters. Consider ternary quantization for ultra-low bandwidth.
- Update scheduling: stagger client uploads by time windows or based on network conditions.
- Delta compression: gzip or lightweight arithmetic encoders after quantization.
Design for opportunistic upload: try to upload on Wi-Fi or during low-power periods. A simple energy policy reduces user disruption.
Model design and optimization for IoT
On-device models must be small and efficient without sacrificing crucial accuracy. Strategies:
- Start with compact architecture families: MobileNetV3, EfficientNet-Lite, or transformer-lite variants for sequence data.
- Use pruning and structured sparsity during training to create efficient serialized models.
- Knowledge distillation: train a small student on-device using a teacher model run centrally.
- Convert to runtime-optimized formats: TensorFlow Lite with delegate support or PyTorch Mobile optimized through quantization-aware training.
One critical decision: train architecture on-device or only fine-tune last layers. Fine-tuning small head layers reduces compute and bandwidth but limits personalization power.
Implementation walkthrough: client-side loop (pseudocode)
The code below sketches a minimal client procedure. It’s platform-agnostic; replace runtime calls with your device SDK.
# Client-side federated step (simplified)
def client_step(local_model, local_data, optimizer, epochs=1):
# load model weights from global checkpoint if provided
for epoch in range(epochs):
for batch in local_data:
optimizer.zero_grad()
outputs = local_model(batch.inputs)
loss = compute_loss(outputs, batch.labels)
loss.backward()
optimizer.step()
# compute model delta to send
delta = extract_delta(local_model)
# optionally sparsify and quantize delta
compressed = compress_update(delta)
# sign and encrypt update
signed = sign_update(compressed)
encrypted = encrypt_for_aggregator(signed)
send_update(encrypted)
Key implementation details:
extract_deltacomputes difference between current local model and received global snapshot to shrink payload.compress_updateapplies pruning, quantization, and delta encoding.sign_updateprovides attestation of device identity while still respecting privacy policies.encrypt_for_aggregatorensures channel confidentiality; combined with secure aggregation prevents single-update inspection.
Server-side aggregation will unwrap encrypted blobs, run secure aggregation, apply DP noise, and update the global model.
Handling heterogeneity and stragglers
- Client selection: prefer clients with recent activity and adequate resources, but sample randomly to avoid bias.
- Partial participation: design aggregation to weight updates by effective sample size on-device rather than equal weights.
- Adaptive epochs: allow clients with more compute to run more local epochs, balanced by learning rate tuning server-side.
When you allow heterogeneity, tune the server optimizer to handle stale or skewed updates. Federated Averaging with momentum on server often helps.
Monitoring, validation, and rollback
On-device FL needs rigorous validation. Central validation on held-out data is necessary but insufficient. Add these measures:
- Canary deployments: roll a new model to a small subset for real-world validation.
- Client-side evaluation hooks: let clients run a small validation set and report secure, aggregated metrics.
- Drift detection: monitor distributional shifts and error trends to trigger model retraining or architecture changes.
- Fast rollback: maintain previous model versions and a deployment strategy to revert quickly if metrics degrade.
Production considerations: scaling and costs
- Orchestrate rounds to limit concurrent uploads and avoid backend spikes.
- Use cost-effective storage for model checkpoints with immutable versioning.
- Store only aggregates and DP-protected metrics to reduce data retention risk.
- Automate security audits for client SDKs and cryptographic primitives.
Example deployment choices
- Lightweight devices with microcontrollers: consider on-device tinyML inference only, and run FL on slightly more capable gateways.
- Mid-range devices: use TensorFlow Lite or PyTorch Mobile with hardware acceleration when available.
- Gateways and edge servers: act as proxies for devices that lack direct aggregator access, batching updates for connectivity reliability.
Summary and checklist
A concise checklist you can use in design reviews:
- Architecture
- Device client, secure aggregator, monitoring pipeline defined
- Support for intermittent connectivity and staggered uploads
- Privacy
- Secure aggregation protocol chosen and tested for dropouts
- Differential privacy parameters calibrated for expected participation
- Communication
- Quantization, sparsity, and delta encoding implemented
- Upload scheduling and Wi-Fi/off-peak policies in place
- Model
- Compact architecture selected for device class
- Pruning, distillation, or quantization-aware training applied
- Decision on fine-tuning head vs full-model training documented
- Ops
- Canary deployment, drift detection, and rollback procedures ready
- Cost estimates for round orchestration and storage accounted
- Security
- Device attestation and update signing in place
- Regular cryptographic and SDK audits scheduled
> Final note: start small, measure aggressively. The core engineering effort is not the ML algorithm but the systems work to make on-device FL robust under device churn, limited resources, and real-world network constraints. When privacy, efficiency, and operability align, on-device FL unlocks personalization at scale without moving raw data off devices.