Prompt Security Playbook: Defense-in-Depth for Enterprise LLM Copilots
Practical playbook to design defense-in-depth for enterprise LLM copilots to prevent prompt-injection, data exfiltration, and model manipulation.
Prompt Security Playbook: Defense-in-Depth for Enterprise LLM Copilots
Prompt-based copilots are now a standard productivity surface in enterprises. They also introduce new, high-impact attack vectors: malicious prompts, covert data exfiltration, and model manipulation. This playbook shows how to build a pragmatic, defense-in-depth architecture that reduces risk while preserving developer velocity.
This is a practitioner guide. It focuses on controls you can implement now, integration points, and trade-offs between usability and assurance.
Threat model: what you’re defending against
Start by defining a clear threat model. Common adversaries and goals include:
- Malicious internal user or compromised account trying to extract sensitive documents.
- External attacker who injects crafted text through any input channel (chat, file upload, API) to alter model behavior.
- Supply-chain threats: compromised prompt templates or model updates that change behavior.
- Accidental misuse that exposes data or grants dangerous instructions to downstream systems.
Assets you must protect:
- Sensitive context (documents, keys, PII).
- Execution endpoints (APIs, shell access, automation workflows).
- Model integrity and templates that shape responses.
Controls should minimize the blast radius of a successful prompt exploit and enable fast detection and response.
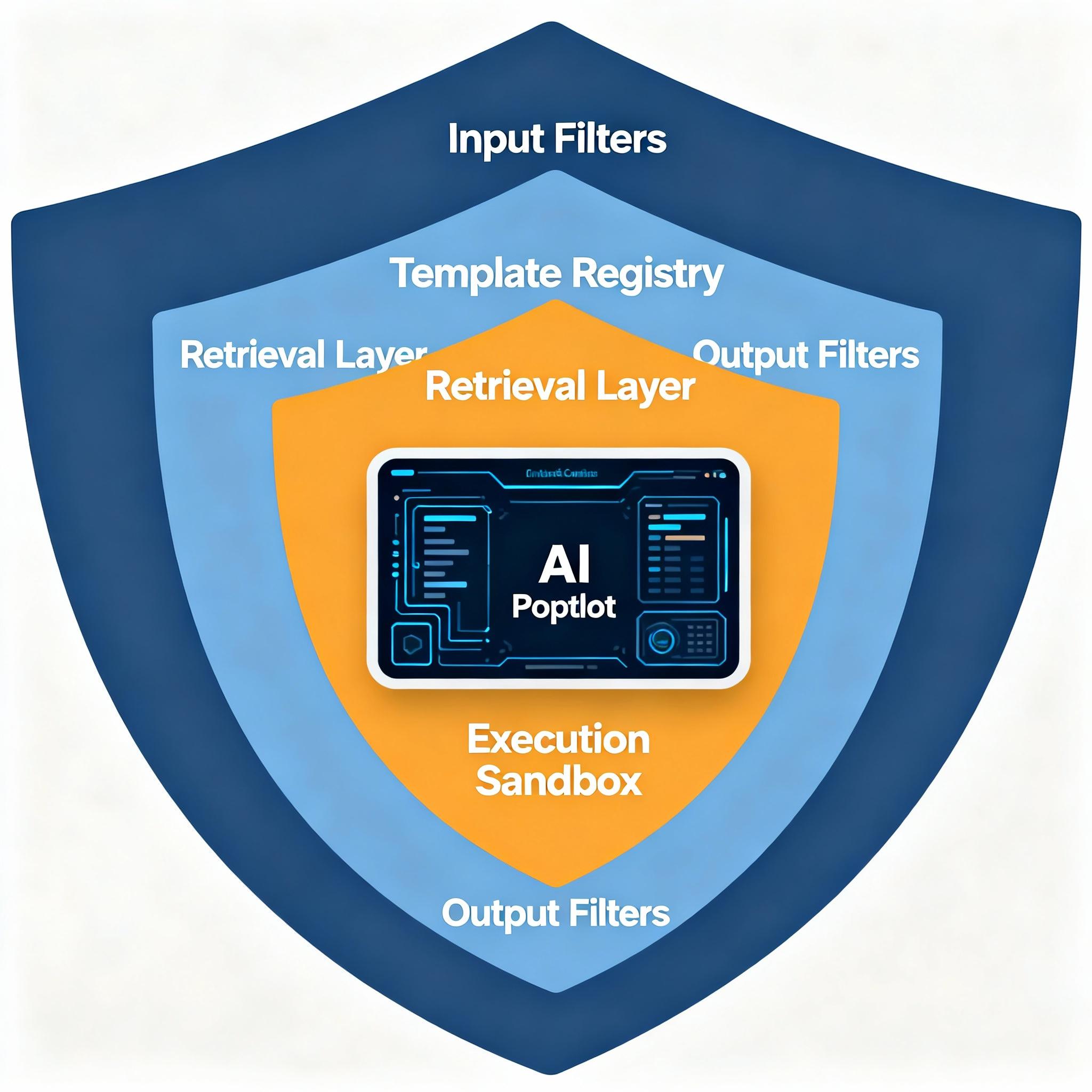
Defense-in-depth layers
Treat prompt security like any other security domain: multiple independent controls that together make exploits expensive and detectable.
1) Input validation and classification
Block or flag obviously dangerous inputs before they reach the prompt pipeline.
- Enforce allowed content types and size limits for uploads.
- Use classifiers to detect prompts that request secrets, system instructions, or data-exfil patterns (e.g., “show me all SSNs”).
- Rate-limit and throttle untrusted users.
Practical tip: run a lightweight regular expression and ML classifier pipeline pre-ingest to mark risky sessions for additional controls.
2) Template hardening and instruction anchoring
Free-form prompts are a major risk. Use structured prompt templates and avoid concatenating user content into system instructions without constraints.
- Maintain a trusted registry of prompt templates with versioning and code review.
- Prefer templates that explicitly separate
systeminstructions fromuserinputs and avoid embedding executable instructions inside user-supplied text. - Anchor the model by providing system-level constraints like: “Answer using only the documents provided. Do not fabricate facts. If you cannot answer, say ‘I don’t know.’”
Template hardening reduces the effectiveness of injection attacks that try to override intent.
3) Context minimization and retrieval controls
Don’t give the model more context than necessary.
- Use retrieval-first patterns: fetch only relevant doc snippets, redact sensitive fields, and synthesize reference citations.
- Limit context window to a deterministic set of documents and metadata tags.
- Track provenance: include opaque document IDs rather than raw content where possible.
When you must include sensitive content, add additional guards (see output filtering and runtime controls).
4) Output filtering and transformation
Assume the model will attempt to produce anything; filter outputs before they reach users or downstream systems.
- Apply DLP (data loss prevention) checks to detect account numbers, API keys, secrets, or PII. Replace or redact matches.
- Use neural-based classifiers to detect policy-violating content or instruction-following attempts that exceed scope.
- Transform output to a safe canonical format (e.g., JSON with vetted fields) rather than raw prose when automation is involved.
5) Execution sandboxing and privilege separation
When copilots can trigger actions (deploy, run SQL, call APIs), never run with full privileges.
- Implement a policy engine that maps model-generated action requests to a least-privilege executor.
- Require human approval for high-risk actions and provide explainable audit trails.
- Use short-lived credentials, capability tokens, and scoped service accounts for every automated action.
6) Monitoring, telemetry, and red-teaming
Detection is as important as prevention.
- Log full prompts, model responses, metadata, and decision path (which retriever hits, which template used). Keep these logs secure and access-controlled.
- Build detectors for anomalous prompt patterns (spikes in secret-extraction queries, or repeated attempts to override system instructions).
- Regularly run red-team exercises and adversarial prompt generation against your templates and filters.
7) Model governance and deployment controls
Treat prompt templates and model configurations like code.
- Require code-review, CI checks, and staged rollouts for prompt templates and model parameter changes.
- Pin versions of models and retrievers for production to avoid silent behavior drift.
- Use canarying and shadow traffic to validate new prompts and models before full rollout.
A simple sanitizer example
Below is a practical sanitizer pattern that strips dangerous instruction verbs and detects likely attempts to inject system-level commands. Use it as a building block, not a full solution.
def sanitize_user_input(text):
"""Simple sanitizer: remove lines that look like high-privilege instructions."""
forbidden_starts = ["ignore previous", "forget all", "disable", "override system", "give me the secret"]
safe_lines = []
for line in text.splitlines():
lowered = line.strip().lower()
if any(lowered.startswith(s) for s in forbidden_starts):
# replace with warning token that will be handled by downstream logic
safe_lines.append("[REDACTED-INSTRUCTION]")
else:
safe_lines.append(line)
return "\n".join(safe_lines)
Use this sanitizer before inserting user content into system templates. Pair it with classifiers that score the likelihood of malicious intent and route high-risk content through stricter policies.
Integrations and engineering trade-offs
-
Latency vs. Security: Adding classifiers, retrieval filters, and DLP increases response time. For low-risk interactive scenarios, keep light-weight checks; for automation or privileged contexts, accept additional latency.
-
Usability vs. Restrictiveness: Overzealous redaction frustrates users. Provide transparent error messages and escape hatches (audited, ticketed approvals) to handle false positives.
-
Centralized vs. Embedded Controls: Centralized policy services make consistency easier; embedding soft checks in client apps provides early defense. Use both: client-side pre-checks and server-side enforcement.
Incident response and playbooks
When you detect a potential data-exfil attempt:
- Immediately throttle or suspend the session token.
- Snapshot prompt + context + model response and store in secure evidence store.
- If credentials were leaked, rotate impacted secrets and revoke sessions.
- Run a root-cause analysis: how did the content reach the model? Which template and retriever were used?
- Update templates, classifiers, and add unit tests to prevent recurrence.
Automate as much of this as possible and run tabletop exercises with security, product, and legal teams.
Metrics and success criteria
Track metrics to measure the effectiveness of your defenses:
- False positive / false negative rates for classifiers.
- Number of blocked data-exfil attempts over time.
- Mean time to detect and respond (MTTD / MTTR) for incidents.
- Percentage of templates under version control and reviewed.
Use these to prioritize engineering work and refine detection rules.
Summary checklist (operational)
- Maintain a registry of vetted prompt templates with code review and versioning.
- Pre-process inputs with classification and sanitization.
- Minimize context exposure: retrieve only necessary document snippets and redact sensitive fields.
- Filter outputs with DLP and policy classifiers before delivery.
- Enforce least-privilege for any execution; require human approval for high-risk actions.
- Log prompts, responses, and decision metadata securely; run anomaly detection.
- Canary prompt/template/model changes and practice red-team exercises regularly.
- Have an incident playbook for throttling, evidence capture, credential rotation, and remediations.
Prompt security is a program, not a one-off project. The right balance between protection and productivity comes from incremental controls, rigorous telemetry, and continuous red-teaming. Implement the layers above, run experiments to measure impact, and iterate.